反编译apk res\values-en\strings.xml:154: error: invalid symbol: ‘do’ 错误解决
出现这个错误的原因是apk加密混淆时按 a、b、c…aa、ab 的顺序重新生成的资源名称结果轮到 do 和关键字一样了。解决办法是重命名,直接把所有的资源文件全部打开然后替换 “do” 到 “d_o” , “if” 到 “i_f” 。就可以解决这个问题。
出现这个错误的原因是apk加密混淆时按 a、b、c…aa、ab 的顺序重新生成的资源名称结果轮到 do 和关键字一样了。解决办法是重命名,直接把所有的资源文件全部打开然后替换 “do” 到 “d_o” , “if” 到 “i_f” 。就可以解决这个问题。
稍微记一下,现在 django 关调试模式需要配置 ALLOWED_HOSTS = [] 否则 Bad Request (400)。
ALLOWED_HOSTS 填的是允许的域名列表,可以用 ‘*’ 来泛匹配。
今天早上部署 django 网站的时候被坑的不轻,根本找不到错误日志,最后无奈本地关调试模式 runserver 后看到提示才知道的。
http://www.voidspace.org.uk/python/modules.shtml#pycrypto 有 windows 下编译好的包,直接安装就可以。
import hashlib
from Crypto.Cipher import AES
from binascii import b2a_hex, a2b_hex
>>> def encrypt(key,text):
# 密钥key 长度必须为16(AES-128), 24(AES-192),或者32 (AES-256)Bytes 长度
# 所以直接将用户提供的 key md5 一下变成32位的。
key_md5 = hashlib.md5(key).hexdigest()
# AES.MODE_CFB 是加密分组模式,详见 http://blog.csdn.net/aaaaatiger/article/details/2525561
# b'0000000000000000' 是初始化向量IV ,16位要求,可以看做另一个密钥。在部分分组模式需要。
# 那个 b 别漏下,否则出错。
cipher = AES.new(key_md5,AES.MODE_CFB,b'0000000000000000')
# AES 要求需要加密的内容长度为16的倍数,当密文长度不够的时候用 '\0' 不足。
ntext = text + ('\0' * (16-(len(text)%16)))
# b2a_hex 转换一下,默认加密后的字符串有很多特殊字符。
return b2a_hex(cipher.encrypt(ntext))
>>> def decrypt(key,text):
key_md5 = hashlib.md5(key).hexdigest()
cipher = AES.new(key_md5,AES.MODE_CFB,b'0000000000000000')
t=cipher.decrypt(a2b_hex(text))
return t.rstrip('\0')
>>> encrypt('111','012340000000000000000000000000000000000000056')
'a37e0dda14a9678fcc82b8e16387c498c7206122195b1b91269a637322d776c48a28342d24b31879a35a0e77480a1dab'
>>> decrypt('111','a37e0dda14a9678fcc82b8e16387c498c7206122195b1b91269a637322d776c48a28342d24b31879a35a0e77480a1dab')
'012340000000000000000000000000000000000000056'
>>>
一个虚构的场景,某受害者在某大论坛看到一篇标题党的帖子,打开了发现有很多很小的打不开的图片,就发帖声讨楼主。却不知道路由器的dns已被攻击者修改了。下次受害者打开 chewang.net 跳转到山赛hao123网站是小事。打开淘宝购买东西付款时没注意地址栏没有锁标志或者没注意付款界面显示的付款内容就付款了,结果等了几天没收到货找淘宝才知道自己根本没给卖家付款,而是把钱打给攻击者了,这就很悲剧了。
当然了,上面那个场景并不容易实现,有些要求,比如路由器弱口令、被攻击者猜到了路由器IP,攻击者猜对路由器型号,才会受到攻击。看似艰难,但是很多路由器是默认密码,IP地址更大部分都是192.168.1.1,主流的路由器型号也不是很多,受害者就很多了,听说13年一次大范围攻击中在网的路由器4%的中招了。详细情况大家可以搜索“路由CSRF”。这里说一下解决办法:1.修改默认密码,2.修改默认路由器地址,3.经常去更新路由器固件(祈祷路由器厂家在路由器有漏洞时更提供新固件)。
上面写得是用户浏览网站中的招,但是实际上还有另外一个中招的可能,部分路由器默认对外网公开了一些服务,例如web、telnet 等服务,虽然只有极少数路由器有这个问题,但是也需要注意,如果设备再有后门密码,或者登陆验证跳过就被杯具了。有些人会扫整个互联网,尝试找到有问题的设备的哦。
这一块就不再细说了,各个品牌的路由器问题并不统一,而且在不断出新的问题。这里有国外的一份路由器漏洞列表,但是并不全,甚至一些国内品牌都不存在,只能作参考。地址是: http://routerpwn.com/ 。
建议只能是修改默认密码,修改默认IP,自己确认没有在外网开web、telnet 等服务,在更新到最新固件,这样一般就没什么大问题了。
互联网从1969至今一运行了45年了,但是其安全性并不是很好。我打算列出一些我知道的安全问题。本来打算做一个零基础的科普,结果发现细节太多了,零基础科普再说吧,下面的内容需要相应的基础知识。
先从局域网开始,大约10年前的集线器就不说了,那个根本没有安全性可言。目前大部分家庭及网吧使用的交换机也是有安全问题的,ARP 攻击及 CAM 攻击是两个比较明显的安全问题。
先说一下 ARP 攻击,这个现在已经烂大街了,就是发虚假的ARP包欺骗其他计算机,使得其按攻击者的意图错误的设置自身的 ARP 表,造成攻击者可以将受害者对特定IP的访问引导至特定的网卡硬件地址(并不一定是真实的硬件地址,可以是伪造的)的计算机。典型的攻击例子是攻击者电脑开启IP转发功能,广播IP地址是网关IP、硬件地址是自身的 ARP回应包,使得局域网所有电脑会将上网的上行流量发送到攻击者电脑再由攻击者电脑转发给真实网关,使得攻击者可以截获所有明文的登录用户名及密码等数据(关于 https 加密的下面在单独说明)。
如果是仔细些其实还可以向路由器发伪造的arp包,使得下行流量也会经过攻击者。还可以同时使用js缓存投毒,将自身伪造的 Jquery 等库插入被攻击者浏览器缓存,使得 arp 虚假广播结束后也可以持续几天甚至几个月的时间控制被攻击者浏览器大部分网站,详细信息单独介绍。
受影响范围:基本上所有的家庭网络、大部分WLAN网络、很少的网吧、大部分办公电脑。解决方法:1.全局域网ARP绑定,麻烦些,需要网关和所有计算机都得双向绑定。2.VLAN端口隔离,这个有个缺陷是局域网普通电脑无法互相通信了,最常见的windows文件共享、打印机共享、局域网联机游戏对战、机顶盒等手机遥控遥控等功能全部无法使用,这个成本还可以,有不少便宜的支持 VLAN 端口隔离的交换机,但是也只能保护上行流量,无法保护下行流量(感谢 semicircle21@v2ex 补充)。3.程控交换机绑定端口IP及MAC,这个成本就高了。
然后就是 CAM 攻击了。交换机和集线器的区别就是一般转发包时会根据包的目的MAC地址将包转发到对应的端口,而不是广播到所有的包。交换机是通过各个端口发出来的包的源 MAC 来确定这个端口连接着的设备的 MAC 地址的,然后会存放到交换机的 CAM 表里面。但是如果交换机碰到的一个包的目的MAC地址在 CAM 表里面不存在怎么办?交换机就会退化为集线器,向所有端口广播这个包。所以 CAM 溢出攻击是通过发送大量的不同源MAC地址的包塞满 CAM 表,造成正常的 CAM 记录被挤掉,使得交换机退化为集线器,然后开网卡混杂模式就可以监听到整个局域网的流量提取用户名密码等数据了。
还有其实也可以仔细的操作,并不需要溢出CAM表,攻击者可以高速的以路由器MAC地址为源地址来发包,使得交换机认为攻击者持有路由器MAC地址而将发送到路由器MAC地址的数据转发给攻击者,完事后攻击者还可以广播网关IP的ARP请求包来使得路由器发ARP回应包来恢复交换机对网关的绑定。一般路由器再次发包交换机就会再次将MAC地址绑定回路由器所在的交换机端口,一般路由器都很繁忙,所以 CAM 攻击并不能完整的获得整个网络上面的数据。
受影响范围:所有的非程控交换机,所有的未用VLAN隔离或未做MAC地址和端口绑定的程控交换机。解决办法:1.还是VLAN端口隔离,缺陷和上面的ARP攻击一样,但是也只能保护上行流量,无法保护下行流量(感谢 semicircle21@v2ex 补充)。2.为交换机端口绑定MAC地址,缺点还是和ARP攻击解决办法一样,成本高,维护麻烦。
接着说一下现在大范围普及的 WLAN 吧。WLAN 分为两个方面,连接别人的 WLAN 热点有可能被钓鱼攻击,WLAN 热点本身有可能被人攻击。先说钓鱼攻击,攻击者伪造一个移动的 cmcc 的热点,受害者当成真实的移动cmcc了上去,输入了cmcc用户名密码就会被攻击者把账号密码偷到手了,受害者就有可能被攻击者盗用 wlan 账号,电话费就… 如果攻击者用心点,弄个4G上网卡或者直接用受害者的账号连接到真实的cmcc上面去,使得受害者还可以上网,那还可以捕获到用户的所有上网流量,所有明文的密码被攻击者捕获了(同上面,https 加密的问题单独在讲)。甚至还可以更进一步向ARP攻击一样做js缓存投毒,使得受害者即使断开了与虚假 wlan 网络的连接一样会收到攻击者的控制,持续时间从几天到数月不等。
不要以为不连接cmcc之类的公共网络,只连接单位的、商场的、熟悉的 wlan 就安全了,攻击者其实可以通过将真正的wlan击垮,而自己搭建一个同名的wlan来钓鱼。甚至有部分运营商定制机只要碰到名称是运营商名称的 wlan 就自动连接,更加容易被攻击。受影响范围:1.所有的无密码的 wlan 都有可能是伪造的。2.所有的密码公开的或者可被破解的 wlan 都有可能是伪造的。解决办法:实在不确定 wlan 安全性通过 wlan 上网的时候就挂vpn吧。
WLAN 热点本身也有可能被攻击。无密码 WLAN 就不用说了,WEP加密的密码可轻松被破解,WPA加密也不建议使用了。目前 WPA2 加密还是安全的,前提是关闭 WPS 功能及使用高强度密码。不过目前的问题是大部分新路由器都默认开启 WPS 功能,使得攻击者可以在数小时内破解 wlan 密码,之后是简单的蹭网还是像本文开头介绍的 ARP 攻击来攻击整个局域网或者击垮本wlan建一个同名同密码的钓鱼wlan甚至直接攻击路由器修改dns长时间控制着这个 wlan 就不好说了。关于攻击路由器的可行性下面再单独说明。也可以通过开启无线路由器的客户隔离功能来减少一些影响,但是这个相当于交换机的vlan,会像arp攻击里面介绍的一样影响很多功能,而且无法拦截对路由器的攻击,不建议家庭使用,强烈建议公共场所 wlan 使用。对了还有另一个安全隐患,wlan万能钥匙之类的软件设置不好会共享 wlan 密码,你再好的加密再复杂的密码也没用了。你可能说你不会装这类软件,但是你的家人呢,来串门的亲戚、朋友、同事呢?受影响范围:各种家庭单位wlan。解决办法:1.使用 WPA2 ,关闭 WPS 功能,公共场所wlan开启客户隔离功能,路由器使用最新的固件,路由器管理密码设置为复杂密码,wlan密码设置为复杂密码,为访客建立单独的访客 WLAN 热点(感谢 semicircle21@v2ex 补充)。但是这样也无法解决公共场所 wlan 攻击者建立同名同密码 wlan 的问题,只能客户连接 wlan 的时候挂 vpn 来解决了。
总结一下:有线局域网部分由于必须通过网线接入局域网才能攻击,大部分家庭用户只要保证自己的电脑、机顶盒、手机都使用请更新补丁就问题不大(虽然木马病毒之类的东西能攻击整个局域网,但是你只要保证有个靠谱的杀毒软件就没问题了,一般家庭用户不是重点目标,没人会费工夫做免杀的病毒单独针对你的)。WLAN 部分怎么说呢?在外边不要连接 wlan ,非要用的话需要挂 vpn ,而且 vpn 最好是自己搭建的,我只能给出这个建议了。虽然严格将来连接自己的 wlan 都要挂 vpn ,因为自己的wlan也有可能是攻击者伪造的,但是一般用户不是重点目标,没人专门攻击你的。wlan 热点间传播的病毒目前只出了实验版本,据说效果不好。
局域网部分差不多就这样了,关于路由器及js缓存投毒等之后在单独写。今天先睡了,什么时间想起来再增加一些参考链接吧。
更新:感谢 semicircle21@v2ex 的补充,为访客提供访客WLAN,Port VLAN 一样会被欺骗下行流量(https://www.v2ex.com/t/143975#reply1)。
原创文章。转载请注明:转载自GameXG,谢谢!
原文链接地址:http://www.chenwang.net/2014/11/04/%E5%8E%9F%E5%88%9B-%E4%B8%8D%E5%AE%89%E5%85%A8%E7%9A%84%E4%BA%92%E8%81%94%E7%BD%91%E7%B3%BB%E5%88%971-%E5%B1%80%E5%9F%9F%E7%BD%91%E9%83%A8%E5%88%86%EF%BC%88%E5%90%ABwlan%EF%BC%89/
很早之前专门查过,当时路由器有ARP绑定,无线模式设置的是站模式,结果全部上不去网,路由器显示无线后面的设备的MAC地址全是无线设备的MAC地址。解决办法是设置为 站 WDS 模式或接入点WDS模式。这两天又用到了,怕忘了,记一下。
站模式:会通过无线连接到接入点(即无线AP),但是和网线连接有一个区别是会把 AirOS 后面设备的MAC全部改成桥本身的MAC地址,如果网络模式是网桥模式并且路由器等设备做了ARP绑定就会出现上不了网的现象,需要修改为带WDS的无线模式。
站 WDS 模式:会通过无线连接到接入点(即无线AP),相当于一根网线直接直接连接,不会修改 AirOS 后面设备的MAC地址,如果主路由有ARP绑定推荐本模式或无线接入点WDS模式。
接入点模式:即无线AP模式,允许其他设备炼乳本网络。
接入点 WDS 模式:会自动的和同样 ESSID、密码、同样接入点 WDS 模式的设备自动组网,AirOS 之间自动通过通过无线通信,不需要网线连接,而且每个 AirOS 设备都同时提供无线AP功能,手机设备都可以直接连接进来,应该还提供无缝漫游功能(未实测)。 实测过两个 AirOS 都开接入点 WDS模式,双方之间没有网线连接,网络模式都是网桥模式,其中一个 AirOS 设备通过网线和路由器连接,手机可以连入 AirOS
XML-RPC 编码是个坑,只支持 ASCII 字符串(或二进制缓冲块)。为了安全,只能用 xmlrpclib.Binary 把数据包装一下了。
Python 2.7.5 (default, May 15 2013, 22:43:36) [MSC v.1500 32 bit (Intel)] on win32
Type "copyright", "credits" or "license()" for more information.
>>> from SimpleXMLRPCServer import SimpleXMLRPCServer
>>> import xmlrpclib
>>> def a():
return xmlrpclib.Binary({'a':1})
>>> server = SimpleXMLRPCServer(("localhost", 8000))
>>> print "Listening on port 8000..."
Listening on port 8000...
>>> server.register_function(python_logo, 'python_logo')
Traceback (most recent call last):
File "", line 1, in
server.register_function(python_logo, 'python_logo')
NameError: name 'python_logo' is not defined
>>> server.register_function(a, 'a')
>>> server.serve_forever()
127.0.0.1 - - [22/Apr/2014 22:36:32] "POST / HTTP/1.1" 200 -
Traceback (most recent call last):
File "", line 1, in
server.serve_forever()
File "C:\Python27\lib\SocketServer.py", line 236, in serve_forever
poll_interval)
File "C:\Python27\lib\SocketServer.py", line 155, in _eintr_retry
return func(*args)
KeyboardInterrupt
>>> import json
>>> def a():
return xmlrpclib.Binary(json.dumps({'a':1}))
>>> server.register_function(a, 'a')
>>> server.serve_forever()
127.0.0.1 - - [22/Apr/2014 22:37:27] "POST / HTTP/1.1" 200 -
127.0.0.1 - - [22/Apr/2014 22:37:39] "POST / HTTP/1.1" 200 -
127.0.0.1 - - [22/Apr/2014 22:38:04] "POST / HTTP/1.1" 200 -
Python 2.7.5 (default, May 15 2013, 22:43:36) [MSC v.1500 32 bit (Intel)] on win32
Type "copyright", "credits" or "license()" for more information.
>>> import xmlrpclib
>>> proxy = xmlrpclib.ServerProxy("http://localhost:8000/")
>>> proxy.a()
Traceback (most recent call last):
File "", line 1, in
proxy.a()
File "C:\Python27\lib\xmlrpclib.py", line 1224, in __call__
return self.__send(self.__name, args)
File "C:\Python27\lib\xmlrpclib.py", line 1578, in __request
verbose=self.__verbose
File "C:\Python27\lib\xmlrpclib.py", line 1264, in request
return self.single_request(host, handler, request_body, verbose)
File "C:\Python27\lib\xmlrpclib.py", line 1297, in single_request
return self.parse_response(response)
File "C:\Python27\lib\xmlrpclib.py", line 1473, in parse_response
return u.close()
File "C:\Python27\lib\xmlrpclib.py", line 793, in close
raise Fault(**self._stack[0])
Fault: :must be string or buffer, not dict">
>>> proxy.a()
>>> proxy.a().data
'{"a": 1}'
>>> import json
>>> json.loads(proxy.a().data)
{u'a': 1}
>>>
另一种注册方法:
http://soft.zdnet.com.cn/software_zone/2008/0527/887034.shtml
import SimpleXMLRPCServer
#定义自己的CMS类
class MyCMS:
def getVersion(self):#向外公开版本的方法
return "Powerd By python 0.1a"
cms = MyCMS()
server = SimpleXMLRPCServer.SimpleXMLRPCServer(("localhost", 8888))
server.register_instance(cms)
print "Listening on port 8888"
server.serve_forever()#服务器执行,并监听8888端口
import xmlrpclib
server = xmlrpclib.ServerProxy("http://localhost:8888";)
version = server.getVersion()
print "version:"+version
参考:
https://docs.python.org/2/library/xmlrpclib.html#fault-objects
蜘蛛之前用的pyquery做采集,发现对非正常的网页并不适用,正则表达式更是不能用,目标网站网页乱的一团乱麻,打算重新用lxml的迭代解析功能来做吧。
Python 2.7.3 (default, Apr 10 2012, 23:31:26) [MSC v.1500 32 bit (Intel)] on win32
Type "copyright", "credits" or "license()" for more information.
>>> import lxml
Traceback (most recent call last):
File "", line 1, in
import lxml
ImportError: No module named lxml
>>> import lxml
>>> class EchoTarget(object):
def start(self, tag, attrib):
print("start %s %r" % (tag, dict(attrib)))
print attrib
def end(self, tag):
print("end %s" % tag)
def data(self, data):
print("data %r" % data)
def comment(self, text):
print("comment %s" % text)
def close(self):
print("close")
return "closed!"
>>> from lxml import etree
>>> from io import StringIO, BytesIO
>>> parser = etree.XMLParser(target = EchoTarget())
>>> result = etree.XML("sometext ",parser)
close
Traceback (most recent call last):
File "", line 1, in
result = etree.XML("sometext ",parser)
File "lxml.etree.pyx", line 2723, in lxml.etree.XML (src/lxml/lxml.etree.c:52448)
File "parser.pxi", line 1573, in lxml.etree._parseMemoryDocument (src/lxml/lxml.etree.c:79932)
File "parser.pxi", line 1452, in lxml.etree._parseDoc (src/lxml/lxml.etree.c:78774)
File "parser.pxi", line 960, in lxml.etree._BaseParser._parseDoc (src/lxml/lxml.etree.c:75389)
File "parsertarget.pxi", line 149, in lxml.etree._TargetParserContext._handleParseResultDoc (src/lxml/lxml.etree.c:86190)
File "parser.pxi", line 585, in lxml.etree._raiseParseError (src/lxml/lxml.etree.c:71955)
XMLSyntaxError: AttValue: " or ' expected, line 1, column 15
>>> result = etree.XML("sometext ",parser)
start element {'a': u'aaa', 'b': u'bbb'}
{'a': u'aaa', 'b': u'bbb'}
data u'some'
comment comment
data u'text'
end element
close
>>> result
'closed!'
>>> class EchoTarget(object):
def start(self, tag, attrib):
print attrib
print("start %s %r" % (tag, dict(attrib)))
def end(self, tag):
print("end %s" % tag)
def data(self, data):
print("data %r" % data)
def comment(self, text):
print("comment %s" % text)
def close(self):
print("close")
return "closed!"
>>> result = etree.XML("sometext ",parser)
start element {'a': u'aaa', 'b': u'bbb'}
{'a': u'aaa', 'b': u'bbb'}
data u'some'
comment comment
data u'text'
end element
close
>>> class EchoTarget(object):
def start(self, tag, attrib):
print attrib
print("start %s %r" % (tag, dict(attrib)))
def end(self, tag):
print("end %s" % tag)
def data(self, data):
print("data %r" % data)
def comment(self, text):
print("comment %s" % text)
def close(self):
print("close")
return "closed!"
>>> parser = etree.XMLParser(target = EchoTarget())
>>>
>>> result = etree.XML("sometext ",parser)
{'a': u'aaa', 'b': u'bbb'}
start element {'a': u'aaa', 'b': u'bbb'}
data u'some'
comment comment
data u'text'
end element
close
>>>
使用目标解析器方法
目标解析器方法对于熟悉 SAX 事件驱动代码的开发人员来说应该不陌生。目标解析器是可以实现以下方法的类:
start 在元素打开时触发。数据和元素的子元素仍不可用。
end 在元素关闭时触发。所有元素的子节点,包括文本节点,现在都是可用的。
data 触发文本子节点并访问该文本。
close 在解析完成后触发。
清单 2 演示了如何创建实现所需方法的目标解析器类(这里称为 TitleTarget)。这个解析器在一个内部列表(self.text)中收集 Title 元素的文本节点,并在到达 close() 方法后返回列表。
清单 2. 一个目标解析器,它返回 Title 标记的所有文本子节点的列表
class TitleTarget(object):
def __init__(self):
self.text = []
def start(self, tag, attrib):
self.is_title = True if tag == ‘Title’ else False
def end(self, tag):
pass
def data(self, data):
if self.is_title:
self.text.append(data.encode(‘utf-8’))
def close(self):
return self.textparser = etree.XMLParser(target = TitleTarget(),recover=True)
# This and most other samples read in the Google copyright data
infile = ‘copyright.xml’results = etree.parse(infile, parser)
# When iterated over, ‘results’ will contain the output from
# target parser’s close() methodout = open(‘titles.txt’, ‘w’)
out.write(‘\n’.join(results))
out.close()
在运行版权数据时,代码运行时间为 54 秒。目标解析可以实现合理的速度并且不会生成消耗内存的解析树,但是在数据中为所有元素触发事件。对于特别大型的文档,如果只对其中一些元素感兴趣,那么这种方法并不理想,就像在这个例子中一样。能否将处理限制到选择的标记并获得较好的性能呢?
In [7]: f = StringIO.StringIO(r”””
…:
…:
…:
…:
…:
…:
…:
…:
…:
…:
…:
…:
…: ⑧
…: “””)
http://lxml.de/parsing.html#parsers
The target parser interface
As in ElementTree, and similar to a SAX event handler, you can pass a target object to the parser:
>>> class EchoTarget(object):
… def start(self, tag, attrib):
… print(“start %s %r” % (tag, dict(attrib)))
… def end(self, tag):
… print(“end %s” % tag)
… def data(self, data):
… print(“data %r” % data)
… def comment(self, text):
… print(“comment %s” % text)
… def close(self):
… print(“close”)
… return “closed!”>>> parser = etree.XMLParser(target = EchoTarget())
>>> result = etree.XML(“
sometext “,
… parser)
start element {}
data u’some’
comment comment
data u’text’
end element
close>>> print(result)
closed!
It is important for the .close() method to reset the parser target to a usable state, so that you can reuse the parser as often as you like:
>>> result = etree.XML(“sometext “,
… parser)
start element {}
data u’some’
comment comment
data u’text’
end element
close>>> print(result)
closed!
Starting with lxml 2.3, the .close() method will also be called in the error case. This diverges(分歧) from the behaviour of ElementTree, but allows target objects to clean up their state in all situations, so that the parser can reuse them afterwards.
>>> class CollectorTarget(object):
… def __init__(self):
… self.events = []
… def start(self, tag, attrib):
… self.events.append(“start %s %r” % (tag, dict(attrib)))
… def end(self, tag):
… self.events.append(“end %s” % tag)
… def data(self, data):
… self.events.append(“data %r” % data)
… def comment(self, text):
… self.events.append(“comment %s” % text)
… def close(self):
… self.events.append(“close”)
… return “closed!”>>> parser = etree.XMLParser(target = CollectorTarget())
>>> result = etree.XML(“
some“,
… parser) # doctest: +ELLIPSIS
Traceback (most recent call last):
…
lxml.etree.XMLSyntaxError: Opening and ending tag mismatch…>>> for event in parser.target.events:
… print(event)
start element {}
data u’some’
close
Note that the parser does not build a tree when using a parser target. The result of the parser run is whatever the target object returns from its .close() method. If you want to return an XML tree here, you have to create it programmatically in the target object. An example for a parser target that builds a tree is the TreeBuilder:
>>> parser = etree.XMLParser(target = etree.TreeBuilder())>>> result = etree.XML(“
sometext “,
… parser)>>> print(result.tag)
element
>>> print(result[0].text)
comment
http://lxml.de/tutorial.html
http://www.ibm.com/developerworks/cn/xml/x-hiperfparse/index.html
http://sebug.net/paper/books/dive-into-python3/xml.html
http://alvinli1991.github.io/python/2013/11/12/python-xml-parser—elementtree/
http://pycoders-weekly-chinese.readthedocs.org/en/latest/issue6/processing-xml-in-python-with-element-tree.html
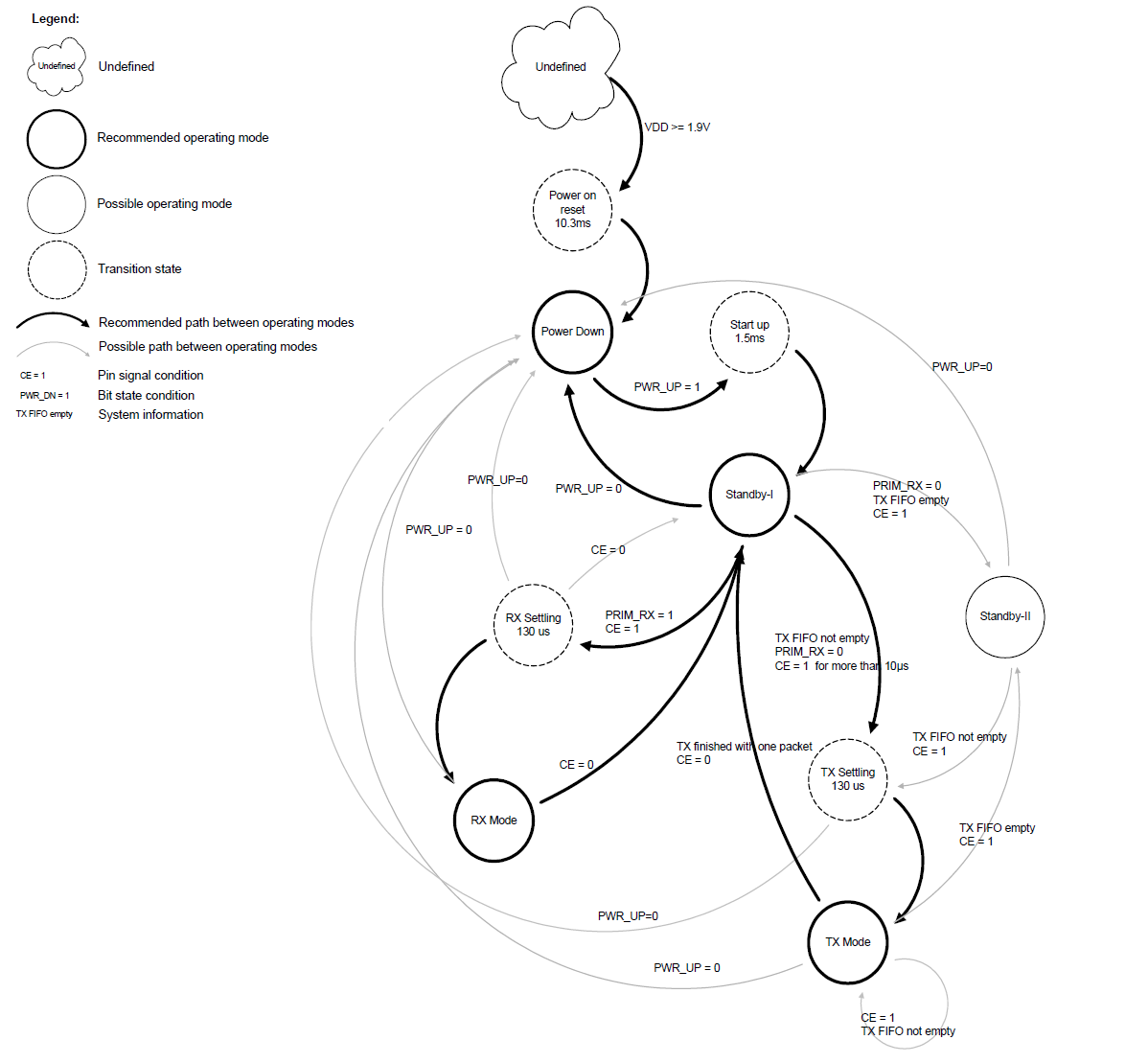
引脚 名称 引脚功能 描述 1 CE 数字输入 RX 或 TX 模式选择 2 CSN 数字输入 SPI 片选信号 3 SCK 数字输入 SPI 时钟 4 MOSI 数字输入 从 SPI 数据输入脚 5 MISO 数字输出 从 SPI 数据输出脚 6 IRQ 数字输出 可屏蔽中断脚 7 VDD 电源 电源(+3V) 8 VSS 电源 接地(0V) nRF24L01 可以设置为以下几种主要的模式, 模式 PWR_UP PRIM_RX CE FIFO 寄存器状态 接收模式 1 1 1 - 发送模式 1 0 1 数据在 TX FIFO 寄存器中 发送模式 1 0 1→0 停留在发送模式,直至数据发送完 待机模式 II 1 0 1 TX FIFO 为空 待机模式 I 1 - 0 无数据传输 掉电模式 0 - - - 关于 nRF24L01 I/O 脚更详细的描述请参见下面的表。 nRF24L01 在不同模式下的引脚功能 引脚名称 方向 发送模式 接收模式 待机模式 掉电模式 CE 输入 高电平>10us 高电平 低电平 - CSN 输入 SPI 片选使能,低电平使能 SCK 输入 SPI 时钟 MOSI 输入 SPI 串行输入 MISO 三态输出 SPI 串行输出 IRQ 输出 中断,低电平使能
增强型的ShockBurstTM 模式 比 ShockBurstTM 模式多了个自动应答、自动重发功能。
nRF24L01 在接收模式下可以接收6 路不同通道的数据,每一个数据通道使用不同的地址,但
是共用相同的频道。也就是说6 个不同的nRF24L01 设置为发送模式后可以与同一个设置为接收模式的
nRF24L01 进行通讯,而设置为接收模式的nRF24L01 可以对这6 个发射端进行识别。数据通道0 是唯一
的一个可以配置为40 位自身地址的数据通道。1~5 数据通道都为8 位自身地址和32 位公用地址。所有的
数据通道都可以设置为增强型ShockBurst 模式。
nRF24L01 在确认收到数据后记录地址,并以此地址为目标地址发送应答信号。在发送端,数据通道0
被用做接收应答信号,因此,数据通道0 的接收地址要与发送端地址相等以确保接收到正确的应答信号。
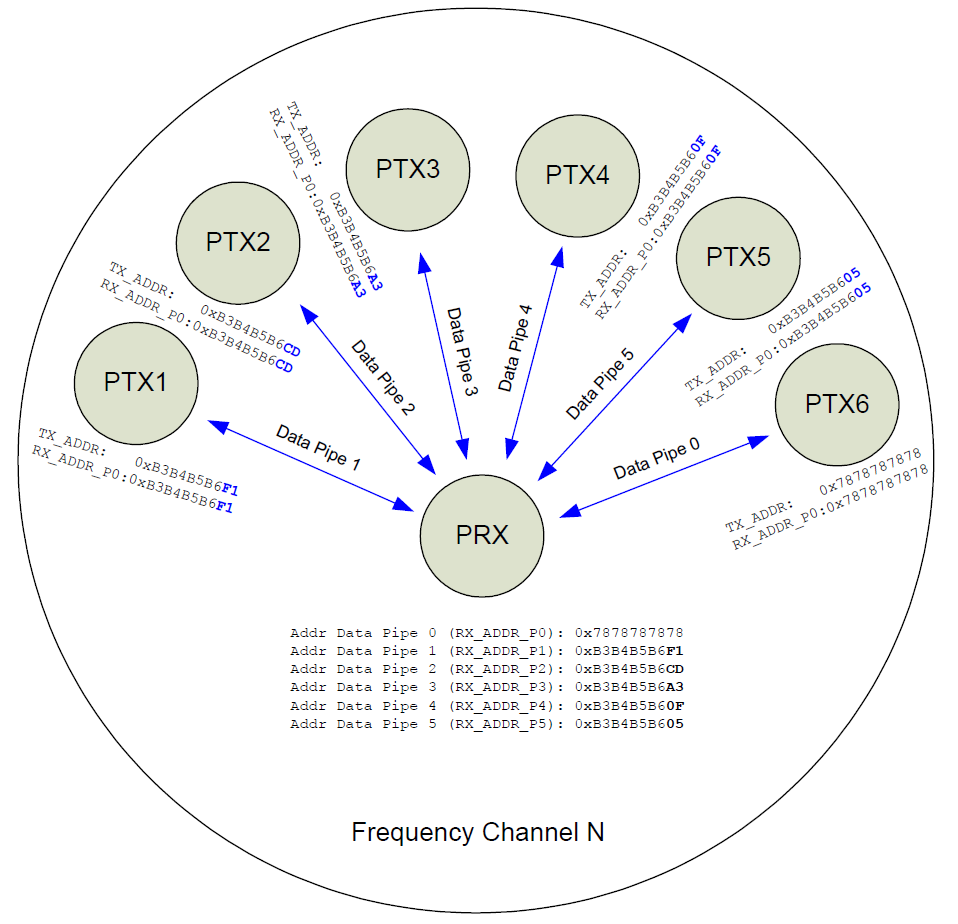
见图5 选择地址举例。
增强型ShockBurstTM 发送模式:
1、 配置寄存器位PRIM_RX 为低
2、 当MCU 有数据要发送时,接收节点地址(TX_ADDR)和有效数据(TX_PLD)通过SPI 接口写入
nRF24L01。发送数据的长度以字节计数从MCU 写入TX FIFO。当CSN 为低时数据被不断的写入。
发送端发送完数据后,将通道0 设置为接收模式来接收应答信号,其接收地址(RX_ADDR_P0)与接
收端地址(TX_ADDR)相同。例:在图5 中数据通道5 的发送端(TX5)及接收端(RX)地址设置如下:
TX5:TX_ADDR=0xB3B4B5B605
TX5:RX_ADDR_P0=0xB3B4B5B605
RX:RX_ADDR_P5=0xB3B4B5B605
3、 设置CE 为高,启动发射。CE 高电平持续时间最小为10 us。
4、 nRF24L01 ShockBurstTM 模式:
限制:
单无线模块只能接受4个设备发送的信息(实际是6个,但是1个为自动应答使用,一个我打算作为默认广播地址使用,就只剩下4个了。其中除了自动应答使用的1个设备地址之外的5个设备的地址非8位部分必须相同。8位地址可以容纳255个设备。),单个设备只能有一个设备地址来接收其他设备发送的信息。
一般200个地址就足够用了,也就是把所有设备除了后8位全部设置成为一样的。
路由设计:
之前被nrf24文档里面的图给坑了,认为为了维持两个设备之间的无线通信必须双方都有一个接收地址设置成为一样的,造成单个nrf24只能和6个设备通信。实际上被那个图给误解了,发数据到另一个设备时只需要把发送地址设置为对方的接收地址(6个中的任意一个)就行,并不需要把自己的接收地址也设置为对方的接收地址(开启自动重发功能时需要将接收地址1设置为发送地址来接受ACK回应),这样设备通信数量的限制就基本上没有了。
文档相关资料:
2、 当MCU 有数据要发送时,接收节点地址(TX_ADDR)和有效数据(TX_PLD)通过SPI 接口写入
nRF24L01。发送数据的长度以字节计数从MCU 写入TX FIFO。当CSN 为低时数据被不断的写入。
发送端发送完数据后,将通道0 设置为接收模式来接收应答信号,其接收地址(RX_ADDR_P0)与接
收端地址(TX_ADDR)相同。
4、 接收到有效的数据包后(地址匹配、CRC 检验正确),数据存储在RX_FIFO 中,同时RX_DR 位
置高,并产生中断。状态寄存器中RX_P_NO 位显示数据是由哪个通道接收到的。
中继设备只需要保存
目前不考虑超过200各设备的情况,真要超过的话以后可以分组的方式来解决。
添加新设备方式:
主控直接和间接(通过已并网的设备中继)的向新设备默认地址广播探测新设备。广播信息如果经过中继的话会记录着中继信息。新设备收到后,会已新设备默认地址按原路径回复信息(包含设备唯一编号)。主控会根据收到的回应来确认找到几个新设备(通过设备唯一编号),各个设备有几条线路可以连接到主控。然后主控为新设备分配设备地址(以后设备地址就固定为这个了)并生成主路由和备用路由信息发给新设备,然后新设备启用收到的新设备地址及路由信息。
个别设备断网时重新入网办法:
< del datetime="2014-01-31T05:43:02+00:00">子设备在主路由信息无法连接主控时会将自身地址设置为本网的新设备默认地址,并循环使用几个主备路由信息来尝试连接到主控。连接到主控则更新路由信息。< /del>
主控在连接不到子设备时会以本网的新设备默认地址为接收地址直接和间接(通过已并网设备中继)的发送探测子设备信息,子设备要是收到则回复,主控等待一段时间根据收到的回复建立新的路由信息并发给子设备,子设备重新并网。
当然,如果主控实在是收不到回应则要么是子设备丢失了本网的地址段(网段非默认网段的情况),要么是之间连接中继或信道环境严重恶化,无法连接,或者子设备掉电或损坏。这些情况只能人工检查和修复了。
>>> import serial
>>> ser = serial.Serial(8)
>>> ser.timeout=1
>>> ser.close()
>>> ser = serial.Serial(8)
>>> ser.timeout=1
>>> ser.readline()
''
>>> ser.write("11111\n") # 每个命令以 \n 结尾
6L
>>> ser.readline()
'received: 11111\r\n'
>>> ser.write("11111\n")
6L
>>> ser.write("22222\n33333333\n") # 可以一次发送多个命令,同样以 \n 结尾。
15L
>>> ser.readline()
'received: 11111\r\n'
>>> ser.readline()
'received: 22222\r\n'
>>> ser.readline()
'received: 33333333\r\n'
>>> ser.readline()
''
>>>
char serial_line[100] ="";
int serial_line_length=0;
void setup()
{
Serial.begin(9600);
Serial.setTimeout(1000); //串口超时 1000 毫秒
}
void loop()
{
if (Serial.available() > 0)
{
// 读取,读到\n或100字符或超时
serial_line_length = Serial.readBytesUntil('\n', serial_line, 100);
serial_line[serial_line_length ]='\0'; // 截断字符串
Serial.print("received: ");
Serial.println(serial_line);
}
}
参考:
http://www.geek-workshop.com/thread-5733-1-1.html
http://wiki.geek-workshop.com/doku.php?id=arduino:arduino_language_reference:serial
http://pythonhosted.org//pyserial/pyserial_api.html