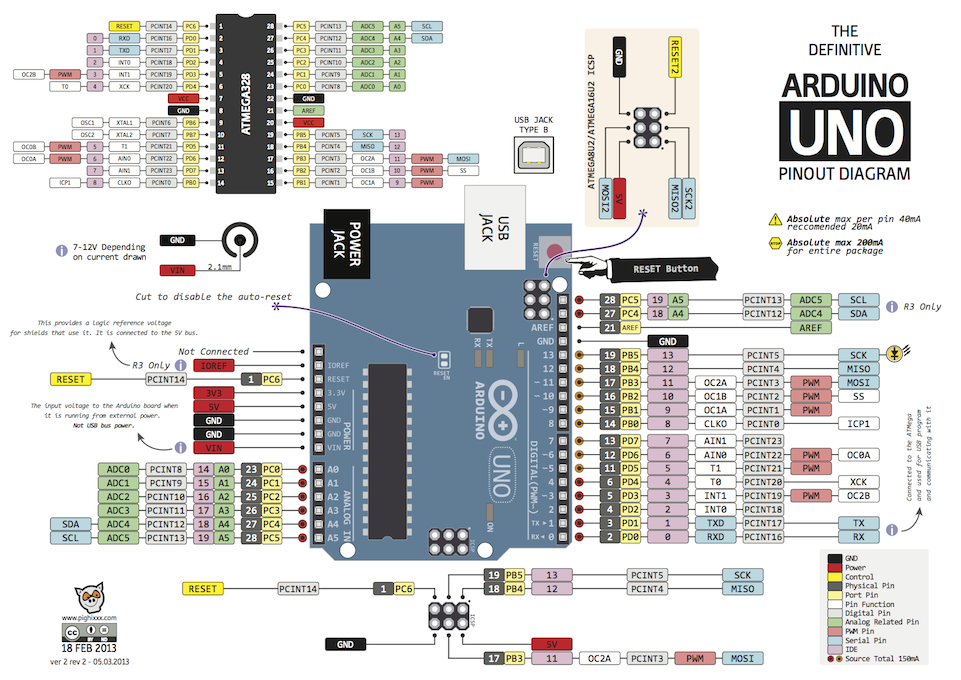
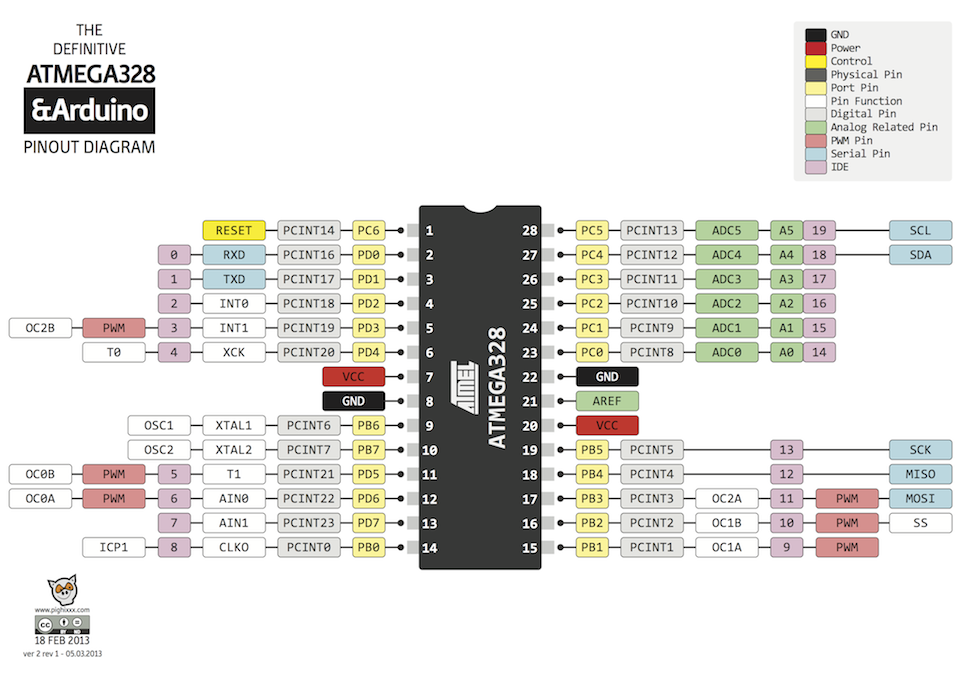
先照着前面几篇文章安装配置好声卡和PocketSphinx ,接着弄好语言模型和词典然后建立下面的03.py文件并执行就可以了。
03.py里用自己路的语音对官方的tdt_sc_8k语音模型做了适应,具体做法可以参考 http://cmusphinx.sourceforge.net/wiki/tutorialadapt 下面附的a.py和b.py是为做适应写的脚本。
实测发现安静环境下语音识别准确率能达到90%以上,但是如果出现其他噪音(其他人的说话声音、电视声音等)识别率就很悲剧。而为了做到全屋的语音识别,却需要把增益开到很大,这就很悲剧了…如果想解决这个问题,只能上麦克风阵列,然后配合傅里叶变换把各个声源的声音独立出来在做语音识别,这样做难度太大,暂时不做这一块。
语言识别相关文章:http://www.chenwang.net/category/%E8%AF%AD%E9%9F%B3%E8%AF%86%E5%88%AB/
03.py
https://gist.github.com/GameXG/647b6c3606a405a47462
#coding:utf-8
import pygtk,gtk,gobject
gobject.threads_init()
import gst
import os
import time
#pipeline=gst.parse_launch('gconfaudiosrc ! audioconvert ! audioresample ! vader name=vad auto-threshold=true ! pocketsphinx name=asr ! appsink sync=false name=appsink')
pipeline=gst.parse_launch('alsasrc ! audioconvert ! audioresample ! vader name=vad auto-threshold=true ! pocketsphinx name=asr ! appsink sync=false name=appsink')
#pipeline=gst.parse_launch('pulsesrc ! audioconvert ! audioresample ! vader name=vad auto-threshold=true ! pocketsphinx name=asr ! appsink sync=false name=appsink')
#pipeline=gst.parse_launch('pulsesrc ! tee name=t ! queue ! audioconvert ! audioresample ! vader name=vad auto-threshold=true ! pocketsphinx name=asr ! appsink sync=false name=appsink t. queue ! audioconvert ! audioresample ! wavenc ! filesink location=o.wav')
def result(asr, text, uttid):
pipeline.set_state(gst.STATE_PAUSED)
print "================== "+text+" ========================="
if text == "朵朵 打开 灯":
os.system("echo 1 > /sys/class/gpio/gpio17_pg9/value")
os.system('mplayer "http://translate.google.cn/translate_tts?ie=UTF-8&q=已打开灯&tl=zh-CN"')
elif text == "朵朵 关闭 灯":
os.system("echo 0 > /sys/class/gpio/gpio17_pg9/value")
os.system('mplayer "http://translate.google.cn/translate_tts?ie=UTF-8&q=已关闭灯&tl=zh-CN"')
else:
#os.system('mplayer "http://translate.google.cn/translate_tts?ie=UTF-8&q=未知命令,'+text+'&tl=zh-CN"')
pass
pipeline.set_state(gst.STATE_PLAYING)
os.system("echo 17 > /sys/class/gpio/export")
time.sleep(1)
os.system("echo out > /sys/class/gpio/gpio17_pg9/direction")
asr=pipeline.get_by_name('asr')
asr.connect('result', result)
asr.set_property('hmm', 'tdt_sc_8kadapt')
asr.set_property('lm', 'TAR3487/3487.lm')
asr.set_property('dict', 'TAR3487/3487.dic')
asr.set_property('configured', True)
pipeline.set_state(gst.STATE_PLAYING)
gtk.main()
# cubie@Cubian:~/yysb/yysb/XueXi$ pocketsphinx_continuous -hmm tdt_sc_8k -lm TAR3487/3487.lm -dict TAR3487/3487.dic
a.py
https://gist.github.com/GameXG/a7e7d1a426ab60a9d79f
#coding:utf-8
# 根据文本文件生成训练语音模型所需的文件
# [email protected]
import sys
import codecs
file_name=None
file_gname=None
if len(sys.argv)==0:
print u'请提供需要处理的文件'
elif len(sys.argv)==2:
file_name = sys.argv[1]
else:
file_name = sys.argv[0]
if file_name[-4]=='.':
file_gname = file_name[:-4]
else:
file_gname = file_name
#f=codecs.open(file_name,'rb','utf-8')
f=open(file_name,'rb')
s=f.readlines()
f.close()
transcription=[]
listoffiles=[]
for i in range(len(s)):
s[i]=s[i].replace(',',' ').replace('.',' ').replace('?',' ').replace(',',' ').replace('。',' ').replace('?',' ').strip()
listoffiles.append('arctic_'+str(i+1))
transcription.append(' %s (arctic_%s)'%(s[i].strip(),str(i+1)))
listoffiles_file = open(file_gname+'.listoffiles','wb')
listoffiles_file.write('\r\n'.join(listoffiles)) #.encode('utf8'))
listoffiles_file.close()
transcription_file = open(file_gname+'.transcription','wb')
transcription_file.write('\r\n'.join(transcription)) #.encode('utf8'))
transcription_file.close()
b.py
https://gist.github.com/GameXG/397851c979f8dd626edf
#coding:utf-8
# 根据 zh_broadcastnews_utf8.dic 为当前字典补全音标
# [email protected]
import sys
import os
file_name=None
if len(sys.argv)==0:
print '请提供需要处理的文件'
elif len(sys.argv)==2:
file_name = sys.argv[1]
else:
file_name = sys.argv[0]
f=open(r'D:\Dropbox\yysb\zh_broadcastnews_utf8.dic','rb')
d={}
i=f.readline()
while(i):
kv=i.split(' ',1)
if len(kv)==2 :d[kv[0].strip()]=kv[1].strip()
i=f.readline()
os.rename(file_name,file_name+'.bak')
def get_dict(name):
if not name:
return ''
for i in range(len(name)):
if d.has_key(name[:len(name)-i]):
return d[name[:len(name)-i]] + ' ' + get_dict(name[len(name)-i:])
return '======= ERR ======='
f=open(file_name+'.bak','rb')
wf = open(file_name,'wb')
ws=[]
for i in f.readlines():
i=i.strip()
if i:
kv = i.split(' ',1)
ws.append('%s %s'%(kv[0],get_dict(kv[0]).strip()))
wf.write('\r\n'.join(ws))
wf.close()